By Alexander Apostolov, PAC World, USA

IEC 61850 has been used for more than 10 years and we already have thousands of digital substations in service all over the world. It brings significant benefits, such as improvements in the reliability, security and efficiency of the operation of electric power systems under different conditions. One of the characteristics of this digitized substations world is the huge amount of data that is becoming available and impossible to process by human beings. That is why there is a growing interest in artificial intelligence (AI) applications in electric power systems.
IEC 61850 based digital substation: One of the main characteristics of the IEC 61850 standard is that it defines the object models of the different components of a protection, automation and control system but does not specify how it should be implemented. In traditional digital substations their architecture is typically distributed with some devices providing the interfaces to the primary substation equipment and other devices performing protection, automation, control, monitoring and recording functions by exchanging information between the process interface devices and themselves. What is common between a distributed system and a centralized system is that the process interface is identical between the two, while the interactions between the distributed devices over the station bus is replaced by interaction over the digital data bus of the central substation servers. The process interface functions can be divided in three main categories:
- Switchgear interface
- Electrical interface
- Non-electrical interface
These functions can be implemented by grouping logical nodes in logical devices. For the logical devices we use the following naming conventions:
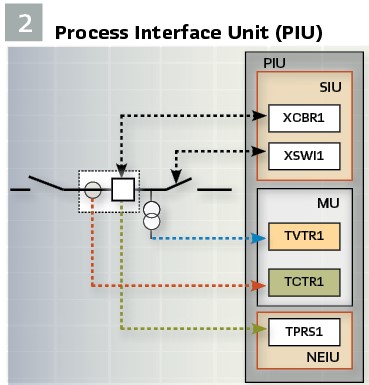
- Switchgear Interface Unit (SIU) digitizes the signals from the switchgear equipment end and provides a binary status and control interface for circuit breakers and switches using GOOSE messages
- Merging Unit (MU) digitizes the analog signals (currents and voltages) into time-synchronized streams of sampled values according to IEC 61850-9-2 of IEC 61869-9
- Non-Electric Interface Unit (NEIU) converts analog signals from non-electric sensors into time-synchronized streams of sampled values according to IEC 61850 9-2 or GOOSE messages according to IEC 61850-8-1
- These logical devices can be placed in individual boxes or can be grouped together in different ways such as:
- Process Interface Unit (PIU) that combines two or more of the functions listed above
- Process Interface IED (PIIED) combines the functionality of a PIU with local protection, control and/or other non-interface functions
The different process interface devices communicate with the rest of the substation protection, automation and control system using the required IEC 61850 services.
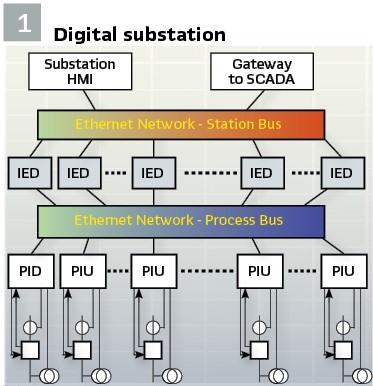
Today most of the existing digital substations have the distributed architecture shown in Figure 1 with the functions located in different multifunctional IEDs communicating over the substation station bus using GOOSE messages.
Based on the data from the process interface devices the IEDs perform different functions such as protection, measurements, automation, monitoring and recording.
Each of the function elements used in the implementation of the above listed functions produces a significant amount of information that can be used to improve the performance of different artificial intelligence-based applications. It is very important to note that all the data from the process, as well as the outputs from the functional elements in the IEDs is time stamped based on the accurate time synchronization using IEC 61850 9- 3 which supports the precise alignment of the data from all different sources. (Figure 2).
It should be noted that even that most of the decisions of artificial intelligence-based applications can be made using the locally available data and information, some of them might be misleading if they did not take into consideration the actual topology of the electric power system and the impact of remotely located equipment. That is why it is important also to receive timestamped information from SCADA or system integrity protection schemes.
Data in Digital Substation
The IEC 61850 based digital substations use various sensors connected to the primary system equipment. All function elements in such systems are represented in the IEC 61850 model by Logical nodes that belong to different groups according to their role in the system.
The sensors in a protection, automation, control, monitoring and recording system belong to the group T. While in Edition 1 of the standard they were only for currents (TCTR) and voltages (TVTR), Edition 2 added many new sensor logical nodes – for temperature, vibration, etc. that are required by condition monitoring functions of the asset management system.
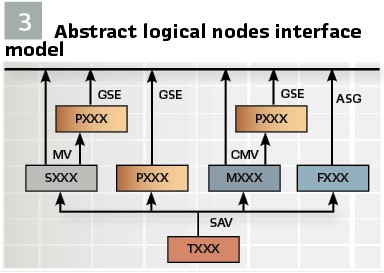
Figure 3 shows an abstract block diagram of the functional decomposition in the IEC 61850 model with the sensor T logical nodes at the bottom sending sampled analog values (SAV) to the function elements that need them – protection (P group), measurements (M group), monitoring (S group). Each logical node represents a function element in the system that is a data source providing data using the services defined in the standard.
The data model hierarchy includes Logical Devices (LD) representing the different functions – protection, control, measurements, monitoring, recording – in the device. The logical device may contain child logical devices representing sub-functions in a hierarchical structure. Logical devices contain logical nodes representing function elements – the building blocks in the model. (Figure 4).
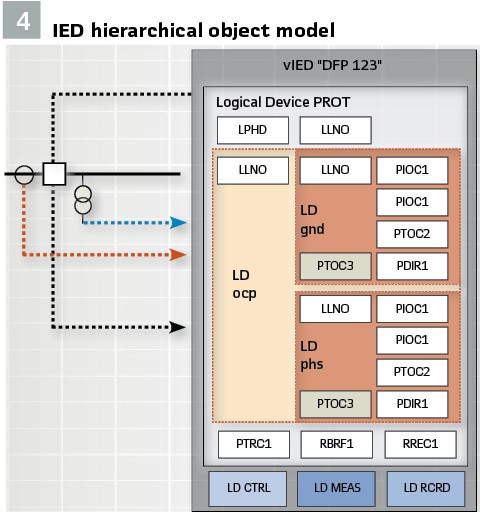
The logical nodes contain data objects belonging to various common data classes. Each data object contains attributes. Some of the data objects and attributes are mandatory, but most of them are optional.
The communication services represented by the control blocks are associated to data sets containing data objects and data attributes. This is the data that is available over the substation communications network and becomes an input into the AI-based components of the system.
The amount of available data in digital substations can be huge, especially when the merging units are publishing streams of current and voltage samples for both protection and power quality and disturbance recording purposes. Today this is based on the implementation agreement known as IEC 61850-9-2 LE. It defines for protection and control applications a sampling rate of 80 samples/cycle at the nominal system frequency. The digital output publishing rate is 4000 frames per second at 50 Hz and 4800 frames/sec at 60Hz with one ASDU (Application Service Data Unit) per frame. For power quality monitoring and disturbance recording the sampling rate is 256 samples/cycle at the nominal system frequency with 8 ASDUs per frame. It is not difficult to imagine the huge amount of data that this represents. The switchgear interface units send GOOSE messages anytime when there is a change of state of the breakers or disconnecting switches.
Since most of today’s advanced IEDs also have embedded phasor measurement units (PMU) that calculate M and P class synchrophasors that may be published 4 times per cycle, the amount of data to be processed by the system further increases.
Any operation of a function in an IED also can be configured to send an event report or to log the data, further adding to the data to be processed by the AI based applications.
Depending on the type of function in some cases we may need to process sampled values streaming in real time, while in others we will be working with recorded data. It is not possible all this data to be processed by humans, that is why we need the help of artificial intelligence platforms to solve the big data problem.
Artificial Intelligence Technologies
Artificial intelligence (AI) is already part of many aspects of our everyday life. The AI concepts and methods have been related to electric power applications for more than half a century. (Figure 5).
There are several reasons that now electric power utilities are turning their attention to artificial intelligence to address many of the challenges they are facing:
- Data availability: The transition of our industry towards a digital grid with merging units and phasor measurement units streaming sampled values and synchrophasor measurements, together with the GOOSE messages and reports from protection and control IEDs generates a large amount of data which, combined with decreasing costs of data storage, is easily available for use. Machine learning can use this as training data for learning algorithms, developing new rules to perform increasingly complex tasks.
- Computing power: Powerful computers and the ability to connect remote processing power through the Internet make it possible the development and implementation of machine-learning techniques that process enormous amounts of data
- Algorithmic innovation: New machine learning techniques, specifically in layered neural networks (also known as “deep learning”) are enabling innovation in different domains of the electric power industry
Today there is a significant, government sponsored development of new algorithms and models in a field of computer science referred to as machine learning. Instead of programming the computer every step of the way, this approach gives the computer instructions that allow it to learn from data without new step-by-step instructions by the programmer. This means computers can be used for new, complicated tasks that could not be manually programmed, as is sometimes the case with protection and control applications in systems with inverter-based DER interfaces. The basic process of machine learning is to give training data to a learning algorithm. A machine learning model may apply a mix of different techniques, but the methods for learning can typically be categorized as three general types:
- Supervised learning
- Unsupervised learning
- Reinforcement learning
Machine learning (ML) encompasses a variety of techniques and methodologies designed to allow computers to learn from and make predictions or decisions based on data. Broadly, these techniques can be classified into three main types: supervised learning, unsupervised learning, and reinforcement learning. Each type has its unique characteristics and is suited to different kinds of problems.
Supervised Learning: Supervised learning is the most prevalent type of machine learning. In this approach, the model is trained on a labeled dataset, which means that each example in the training set is paired with an answer or a label. The goal is to learn a general rule that maps inputs to outputs. It is widely used for regression (predicting a continuous output) and classification (predicting a discrete label) tasks. Popular algorithms include linear regression, logistic regression, support vector machines (SVM), decision trees, and neural networks. The main limitation is the need for a large amount of labeled data, which can be expensive or time-consuming to obtain.
Unsupervised Learning: Unlike supervised learning, unsupervised learning algorithms are used when the information used to train is neither classified nor labeled. This type of ML infers patterns from the dataset without reference to known or labeled outcomes. It is primarily used for clustering (grouping a set of objects in such a way that objects in the same group are more similar to each other than to those in other groups) and association (discovering rules that describe large portions of user data). Common algorithms include k-means clustering, hierarchical clustering, and Apriori algorithm for association rules. However, it can be difficult to evaluate the outcome of unsupervised learning algorithms since there is no gold standard (like labeled data) to compare against.
Reinforcement Learning: Reinforcement learning is somewhat different from both supervised and unsupervised learning. It is about taking suitable action to maximize reward in a particular situation. It is employed by various software and machines to find the best possible behavior or path it should take in a specific situation. It is used in various real-world applications like robotics for industrial automation, game playing (e.g., AlphaGo), autonomous vehicles, and learning simulation environments. Key algorithms include Q-learning, Monte Carlo methods, and Temporal Difference (TD) methods like SARSA. However, reinforcement learning is computationally expensive and often requires a lot of data and computational resources. It can also be challenging to define the environment and the reward system correctly.
Semi-supervised Learning: As an extension to these primary types, there is also semi-supervised learning which uses both labeled and unlabeled data for training – typically a small amount of labeled data with a large amount of unlabeled data. This approach can significantly improve learning accuracy when labeled data are scarce or expensive to obtain. It is useful in scenarios where obtaining a fully labeled dataset is unfeasible, such as in image or speech recognition. Techniques include self-training, co-training, and transductive support vector machines. However, balancing the right mix of labeled and unlabeled data can be tricky.
The choice between these types of machine learning depends on the specific requirements of the application, the availability of data, and the desired outcome. Each type offers different advantages and is equipped to handle different types of problems in data science. Understanding these differences is key to selecting the right approach for a given problem. (Figure 6).
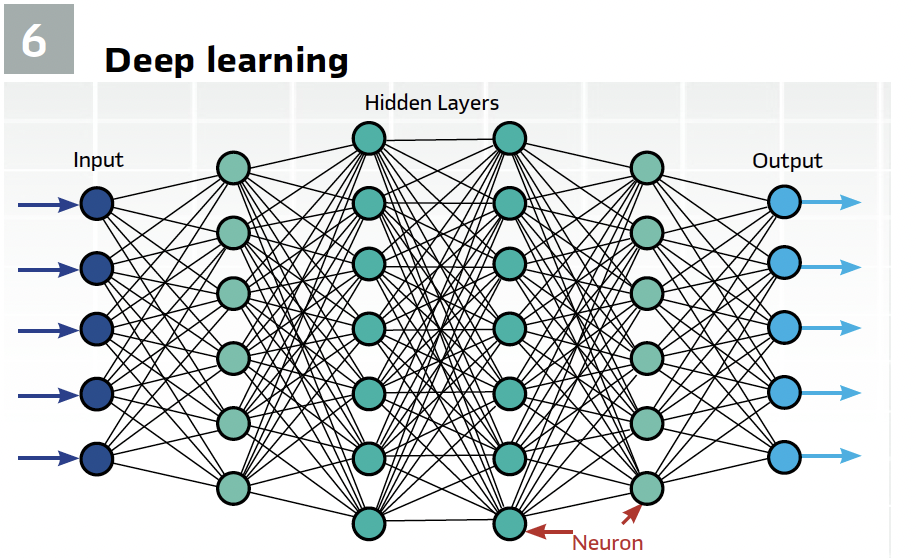
Deep learning is a subset of machine learning. It refers to the number of layers in an artificial neural network (ANN). A shallow network has one so-called hidden layer, and a deep network has more than one (Figure 6). Multiple hidden layers allow deep neural networks to learn features of the data in a so-called feature hierarchy. Nets with many layers achieve some amazing results but are more computationally intensive to train because they pass input data through more mathematical operations than ANNs with few layers.
Deep learning is particularly useful for power systems with its multiple layers, making it effective at processing of data that has many variables and nonlinear relationships, common in dynamic power systems.
Deep learning models are exceptionally good at forecasting, vital for integrating renewable energy sources into the grid efficiently. They can predict solar and wind energy output, anticipate demand fluctuations, and foresee potential system failures or outages. These predictions allow for better planning and can significantly enhance grid reliability and efficiency.
Deep learning algorithms can process and analyze data in real-time, enabling immediate responses to changes in grid conditions. This is essential for tasks such as load balancing and managing instant responses to faults in the power grid. Machine learning models can adapt to new conditions without explicit reprogramming. In the context of power systems, where operating conditions can change rapidly (e.g., sudden weather changes affecting renewable output), the ability of ML models to learn from new data and update their predictions or decisions is invaluable.
Deep learning models scale well with increasing amounts of data, making them suitable for the expanding infrastructure of smart grids that incorporate more sensors, devices, and data points. Additionally, deep learning can integrate different types of data (like weather data, usage patterns, and equipment status) to provide a holistic view of the system’s status.ML algorithms can automate complex decision-making processes, enhancing the efficiency of control systems in the grid. They enable sophisticated control strategies for everything from routine switching operations to emergency response mechanisms, often in an automated or semi-automated manner. This reduces human error and operational costs, while improving the reliability and safety of electrical power systems.
Deep learning can be used alongside reinforcement learning. This is particularly useful in optimizing energy distribution and consumption, managing the storage and dispatch of energy, and in the strategic placement and maintenance of grid components.
Deep learning algorithms are also effective at fault detection and diagnosis in power systems, thanks to their ability to process vast amounts of sensory data in real-time and identify deviations from normal operations. They can pinpoint the type, location, and possible cause of faults, which is crucial for minimizing downtime and preventing cascading failures in the power grid.
Power systems operate in environments with high noise and data corruption potential. Deep learning models are robust to such conditions; they can filter out noise and extract useful information even from corrupted or incomplete data, ensuring reliable operation under diverse conditions.
The selection of machine learning methods or deep learning will depend on the specific PAC related tasks at the different levels of the system hierarchy.
Data for AI Applications
Artificial intelligence technologies are being used or considered for various applications in electric power systems. AI algorithms can continuously analyze data from sensors to detect abnormalities or faults in the system. Using historical data, AI can predict when equipment might fail, allowing for preemptive maintenance to avoid outages. It can optimize demand response programs based on real-time data analysis, improving grid stability during peak load periods. AI systems can dynamically adjust outputs to maintain steady voltage and frequency levels, accommodating fluctuating supply and demand. AI models can predict wind and solar power generation based on weather forecasts, enhancing the grid’s ability to incorporate these variable energy sources and determine the best mix of renewable and non-renewable resources at any given time to maximize efficiency and minimize costs. AI algorithms can manage the operation of energy storage systems to maximize lifespan, efficiency, and financial return. AI helps in effectively pairing energy storage with renewable generation to ensure a consistent energy supply. AI can modify protection system parameters in real-time based on grid conditions, which is essential in complex, interconnected networks. It enables automatic configuration of microgrids for optimal performance during normal operations and when islanding from the main grid during faults. AI can predict future power consumption patterns at various scales to aid in planning and operation. AI-driven systems automatically adjust major power-consuming devices’ operation times based on predicted energy costs and availability.
All of the above listed applications are possible only because the process interface devices and the multifunctional IEDs in digital substations generate huge amounts of data that can be processed by AI based applications which will help solve many of the challenges created by the changing grid.
As was described in this article, different types of data is available in the digital substations with different sampling rates, as well as status and event information. All data is timestamped based on a PTP profile which allows accurate alignment of the data from all various sources for processing by the different AI applications.
The data from the different sources can be grouped in the following categories:
- Raw data represented in the model by streaming sample values from electrical or non- electrical sensors
- Status data from the switchgear and other primary equipment in the substation
- Synchrophasor measurements from the P class or M class from IEDs
- Status data from multi-functional protection and control IEDs
- Event reports from multi-functional protection and control IEDs
- Time synchronization data from different clocks
- Output data from substation level applications
- Data received from remote substation
- Data received from system integrity protection schemes
- Data received from the control center
- Historical fault and disturbance records
- System configuration description (SCD) files
Various combinations of the different types of data can be used as inputs to machine learning algorithms for advanced protection, automation, control and asset management applications.
Biography:

Dr. Alexander Apostolov received MS degree in Electrical Engineering, MS in Applied Mathematics and Ph.D. from the Technical University in Sofia, Bulgaria. He has 51 years’ experience in power systems protection, automation, control and communications. He is presently Principal Engineer for OMICRON electronics in Los Angeles, CA. He is IEEE Life Fellow and Member of the IEEE PES Power Systems Relaying and Control (PSRC) Committee. He is member of IEC TC57 working groups 10, 17 and 19.
He is Distinguished Member of CIGRE. He holds five patents and has authored and presented more than 600 technical papers. He is Editor-in-Chief of PAC World.