Leveraging AI and Digitalized Infrastructure
By Karl Backstrom, Eneryield, Sweden, Petri Hovila and Anna Kulmala, ABB, Finland, Ebrahim Balouji. Eneryield A, Sweden

As society becomes increasingly reliant on electricity, the reliability requirements for electricity supply continue to rise. Early fault prediction can significantly benefit grid operators by enabling them to address potential issues before they lead to failures. This can improve the overall reliability of the grid, resulting in decreased operational costs and reduced revenue loss, as well as ensuring the continuity of power delivery to end users. There are accurate and effective fault prediction solutions available on market, but those require dedicated censoring and installation effort. On the contrast, we can ask how we could utilize existing power system protection, measurement, and monitoring assets as a data source without a need for new sensors? And could we feed the data to vastly evolving artificial intelligence technology?
This article describes a machine-learning based fault prediction solution that operates based on current and voltage measurement data already available at the protection relays.
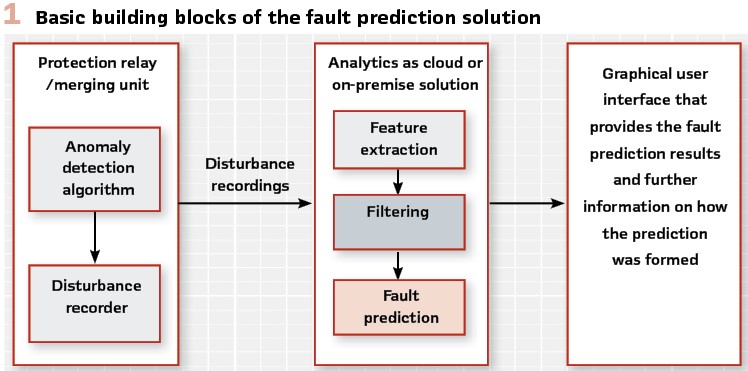
The solution requires few new core elements for data analysis, a triggering method for the recording potential patterns representing evolving faults and a data collection system. The basic building blocks of the solution are depicted in Figure 1.
Anomaly recordings are the most important data source for fault prediction. An example anomaly recording is depicted in Figure 2.
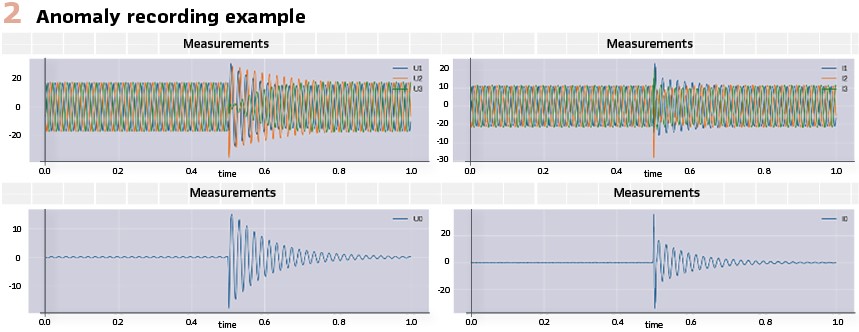
At the moment, only fault recordings are available, but these provide information only from situations when a fault has already occurred. Hence, an anomaly detection algorithm that aims to trigger the disturbance recorder also when there is something abnormal visible in the measurements and not only during fault situations, is required to gather the data for the fault prediction solution. Some additional data sources that can provide further benefits are e.g. phasor measurement units (PMUs), smart meters and weather data. If these data sources are utilized in combination with the anomaly data, the accuracy of the fault prediction can increase but the anomaly data recorded with adequate accuracy is the most important input for fault prediction. It should be noticed that power system digitalization is the key to enable artificial intelligence driven approaches for more resilient and reliable supply.
When a person skilled to the power systems takes a look at the waveforms of disturbance recordings from situations when an anomaly has been detected, this person can assess in a short time whether something unusual is present in the recording. The objective of the fault prediction analytics is to provide similar interpretation without the human in the middle since the network operators are not able to manually go through a large amount of recordings.
Also, some evolving faults might have such fingerprints that the human eye is not able to catch them, but an AI algorithm can still be able to observe them. As a last step, the relevant results are shown to the network operator through a graphical user interface that also explains what the reasoning behind the prediction is.
The analytics can reside either on cloud or as an on-premise solution. Cloud solutions provide easier scalability and, if allowed, can also combine data from different sites. On the other hand, on-premise solutions are favored by many network operators due to e.g. cybersecurity related reasons.
Enhanced analytics and prediction
Artificial Intelligence (AI) and Machine Learning (ML) techniques have been found increasingly useful across applications in the power systems industry for various analytics tasks, such as load forecasting, renewable energy generation prediction, power quality analysis, and asset management.
In this context, the fault prediction solution presented in this article combines advanced AI and ML techniques to analyze data collected primarily from protection relays. At its core is a sophisticated deep learning model that incorporates Long Short-Term Memory (LSTM) layers, a type of recurrent neural network architecture designed to capture long-term dependencies in sequential data. The model processes anomaly recordings, extracts relevant features, and predicts impending faults, their root causes, and approximate locations, effectively capturing temporal dependencies and patterns in the data to enhance the reliability and resilience of power distribution networks.
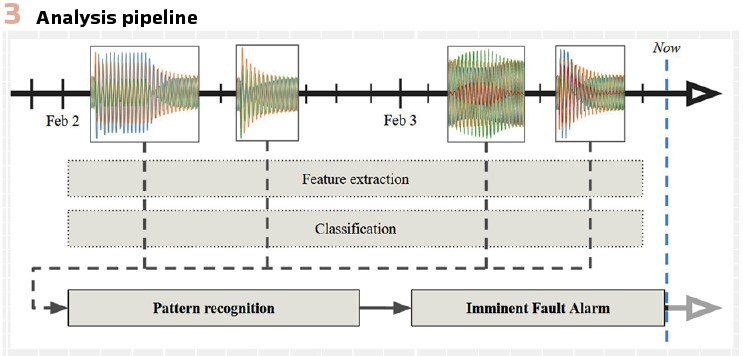
Under the hood: The analysis pipeline, as depicted in Figure 3, consists of several key steps. First, the anomaly recordings undergo extensive preprocessing to extract a rich set of features that capture the essential characteristics of the waveforms. This feature engineering process is crucial for reducing the dimensionality of the data and highlighting the most informative aspects for fault prediction. The extracted features encompass a wide range of statistical measures, such as RMS values, impedances, active and reactive power, harmonics, and phase angles. These features are then aggregated into a compact feature vector that serves as the input to the machine learning model. The feature engineering step is meticulously designed to strike a balance between preserving relevant information and maintaining computational efficiency. The machine learning model architecture is designed to handle the temporal nature of the anomaly recordings effectively. The model leverages a combination of advanced techniques, including LSTM-inspired layers, attention mechanisms, and multi-scale feature fusion.
These components work together to capture both short-term and long-term dependencies in the data, enabling the model to identify subtle patterns and anomalies that may be indicative of evolving faults. The model also incorporates a filtering component that characterizes the relevance of each disturbance recording, which helps to focus the model’s attention on the most informative recordings, reducing noise and improving the signal-to-noise ratio in the input. To further enhance the performance and robustness of the fault prediction system, data augmentation techniques are employed.
These techniques involve applying various transformations and perturbations to the existing anomaly recordings, effectively expanding the training dataset and exposing the model to a wider range of scenarios. Some of the augmentation methods utilized include phase shuffling, amplitude scaling, and the addition of synthetic noise. By incorporating these augmented samples into the training process, the model learns to be more resilient to variations and noise in the input data, improving its generalization ability and overall predictive power.
Case study. To illustrate the prediction procedure in action, let’s examine a specific example from the pilot site, as shown in Figure 4. In this case, the system detected an increased frequency of anomalies due to a transformer issue. These anomalies were characterized by distinct patterns in the voltage and current waveforms, which the model identified as potential precursors to a fault in the transformer. As the anomalies persisted over time with a trend of growing severity, the model’s confidence in an impending fault increased, ultimately leading to a prediction of an imminent failure. On February 25th, a fault occurred in the tap changer transformer, validating the model’s prediction.
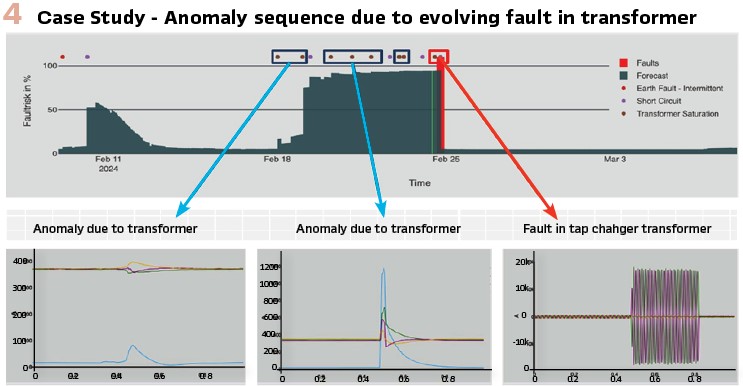
By providing a warning signal already a week in advance, the system demonstrated its capability to anticipate faults, enabling proactive maintenance and reducing the risk of unplanned outages.
Success factors: The fault prediction system’s performance can be attributed to several key factors.
- First, the deep learning model’s architecture, which incorporates LSTM-based computation steps, allows it to effectively capture and learn from the temporal dynamics of the anomaly recordings
- Second, the extensive feature engineering process ensures that the most relevant and discriminative information is extracted from the raw data, providing a rich set of inputs for the model to learn from
- Third, the use of data augmentation techniques enhances the model’s robustness and generalization ability, enabling it to handle a wide range of fault scenarios.
- Finally, the integration of domain knowledge and expert insights throughout the development process has helped to guide the model’s learning and improve its interpretability.
AI transparency and trust: One of the key strengths of the fault prediction system is its ability to provide explainability and transparency regarding the basis for its predictions. The system incorporates advanced techniques that enable operators to understand which specific disturbance recordings and features within those recordings are driving the model’s decision to issue a warning. By presenting this information in a clear and interpretable manner, the system builds trust and confidence in its predictions, allowing operators to make well-informed decisions.
When the model detects an anomaly and predicts an impending fault, it generates a detailed summary that highlights the most influential disturbance recordings and the specific features within those recordings that contributed to the prediction. This summary includes visualizations of the relevant waveforms, along with annotations indicating the key patterns and anomalies detected by the model. Additionally, the system provides a breakdown of the relative importance of each feature, enabling operators to understand which aspects of the data are most indicative of a potential fault. By providing this level of explainability, the fault prediction system empowers operators to validate the model’s predictions and gain deeper insights into the underlying causes of the anticipated faults.
This transparency helps to bridge the gap between the complex inner workings of the AI/ML algorithms and the domain expertise of the operators, fostering a collaborative and trust-based relationship. Operators can leverage their knowledge and experience to interpret the model’s findings, assess the credibility of the predictions, and take appropriate actions based on a holistic understanding of the situation. Moreover, the explainability features of the system facilitate continuous improvement and refinement of the fault prediction model. By analyzing the model’s decision-making process and the features it relies on, domain experts can provide valuable feedback and insights to further enhance the model’s accuracy and robustness. This iterative process of human-machine collaboration ensures that the system remains aligned with the evolving needs and challenges of the power grid, while benefiting from the powerful capabilities of AI/ML technologies.
Future directions: Looking ahead, there are several avenues for further enhancing the fault prediction system. One promising direction is the incorporation of additional data sources, such as weather information, asset health records, and historical maintenance logs.
By leveraging these complementary data streams, the model can gain a more comprehensive understanding of the factors contributing to fault occurrence and potentially improve its predictive accuracy.
Results and KPIs: The effectiveness of the fault prediction system has been rigorously evaluated in a pilot site, and the results are highly encouraging. When evaluated over independent test periods, the system demonstrates a precision, i.e., false positive avoidance, of 100%, and a sensitivity of 64%. I.e., every time an alarm was issued, a fault occurred within 7 days 100% of the time, and out of all the faults that occurred, 64% of them were warned about within 7 days in advance. Here, an alarm is considered to be issued if the estimated risk of incipient fault is over 75%.
These metrics highlight the system’s ability to accurately identify a significant portion of the faults while maintaining a low false positive rate. While it is acknowledged that not all faults are predictable, e.g., faults due to excavators digging up a line, or lightning, the system provides valuable insights and early warnings for a substantial majority of the incidents, enabling proactive measures to be taken.
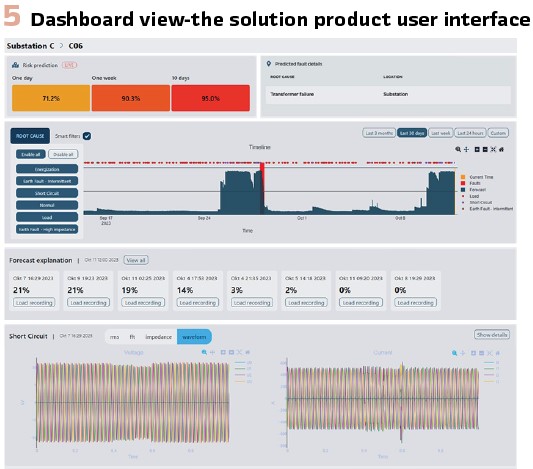
Solution User Interface: The solution is delivered to end users through an intuitive and feature-rich web-based software, deployable both in the cloud and on-premises, offering a user-friendly interface for users to monitor and analyze the health of their network. The GUI (See Figure 5) provides a comprehensive overview of the system’s predictions, including the classification of anomalies, identification of root causes, and estimated fault locations, while incorporating advanced explainability features that empower operators to make informed decisions and take targeted actions. As the system continues to evolve and incorporate additional data sources and advanced anomaly detection techniques, it holds great promise for enhancing the resilience and efficiency of power grids worldwide.
Summary: In conclusion, the fault prediction solution presented in this article represents a significant advancement in the proactive management of power grid reliability. By leveraging state-of-the-art AI/ML techniques, including deep learning models with LSTM-inspired layers and data augmentation, the system demonstrates a high level of precision and sensitivity in predicting impending faults. The successful pilot site evaluation highlights the potential of this technology to provide early warning signs, reduce unplanned outages, and enable proactive maintenance interventions.
Benefits and Enhancements
The fault prediction solution presented in this article offers several significant benefits for power grid operators. One key advantage is that it does not require installing dedicated sensors solely for fault prediction. By leveraging the existing protection relays and measurement devices, the system can be seamlessly integrated into the current grid infrastructure, minimizing implementation costs and reducing the need for extensive retrofitting. This makes the solution highly cost-effective and accessible to grid operators, enabling them to enhance grid reliability without substantial upfront investments.
Early adoption is key. In addition to the core functionality of the system, it is noteworthy that its deployment enables gathering more data over time, which allows the system to record new fault phenomena and behaviors, and continuously evolve and improve its predictive capabilities. By starting the deployment process early, grid operators can maximize the benefits of the system and ensure that it, not only learns diverse and representative datasets, but allows it to adapt to the specific characteristics and challenges of each grid environment.
Extended predictive locationing: Looking towards the future, the fault prediction system holds immense potential for accurate localization of various types of evolving faults. As the system accumulates a rich repository of anomaly recordings and fault data, it can leverage advanced analytics techniques to pinpoint the precise location of incipient faults. This enhanced localization capability can greatly assist maintenance crews in quickly identifying and addressing the root causes of faults, minimizing downtime and enabling proactive actions.
Diverse data sources: Another key strength of the fault prediction system is its flexibility to incorporate new data sources and aggregate information from additional measurement points. The modular architecture of the system allows for the seamless integration of data from various sources, such as phasor measurement units (PMUs), smart meters, and weather forecasts. By combining these diverse data streams, the system can gain a more comprehensive understanding of the factors contributing to fault occurrence and improve its predictive accuracy.
Underground cables: As the power grid continues to evolve, there is a growing trend towards the deployment of underground cables. While underground cables offer several advantages, they also present unique challenges for fault prediction and localization. The fault prediction system presented in this article is well-positioned to address these challenges. By adapting the machine learning models and feature engineering techniques to the specific characteristics of underground cables, the system can provide valuable insights and early warning signs for these critical assets.
As the number of faults in underground cables is typically lower compared to overhead lines, the ability to accurately predict and localize evolving faults becomes even more crucial.
In conclusion, the fault prediction solution presented in this article offers a range of compelling benefits, including the ability to leverage existing infrastructure, evolve over time, and provide accurate fault localization. As the system develops and incorporates new data sources and advanced analytics techniques, it can revolutionize the way faults are predicted and managed in overhead and underground transmission and distribution networks.
Biographies:

Dr. Karl Backstrom is a co-founder and Technical Lead at Eneryield AB. Karl holds a Ph.D. in AI and Machine Learning Algorithms and Systems and has led several research and pilot projects with notable actors such as ABB, LKAB and DNV. Karl has received several awards for his work, including the Best Paper Honorable Mention at IPDPS 2021 and the prestigious SKAPA-prize. His work has resulted in several ventures internationally, as well as multiple patents and publications in the fields of electrical engineering, computer science, and medical imaging.

Petri Hovila is currently working as a senior principal engineer in ABB Electrification, Distribution Solutions and is responsible for research programs. He has been working in various R&D positions over 25 years in protection and control domain. He has authored or co-authored a number of conference papers and is a co-inventor in several patent applications.

Anna Kulmala is currently an R&D Project Manager at ABB Distribution Solutions. She has been leading and working in various European and national projects for more than 15 years. Her interests are focused on several aspects of the future smart grids such as novel distribution network protection concepts, active distribution network management and smart grid architectures. She received the M.Sc. and Ph.D. degrees in electrical engineering 2006 and 2014 from Tampere University of Technology, respectively.

Dr. Ebrahim Balouji holds dual Ph.D. from Chalmers University of Technology’s electrical engineering department. He has developed high-sampling-rate PMU and AMUs in his PhDs according to IEC standards. He also developed AI-based applications for analyzing big data in power systems. In 2021, he received the Gunnar Engstrom honor reward from the ABB Foundation for his research. He is serial entrepreneur, co-founder, and CTO of Eneryield AB, which develops AI-driven software to predict the faults in power systems days and weeks ahead. In 2022, Dr. Balouji received the Outstanding Paper Award from the IEEE Transactions on Industry Applications Society.