By Glenn Wilson, Southern Company, USA
This article aims to lay the groundwork for the discussion of virtual protection systems for those who may not have had exposure to some of the concepts. Many of the technical challenges are themselves worthy of an entire article. However, without a solid understanding of the big-picture, technical deep dives are often lost on the audience that needs to understand them most – the utility. Let’s take a look at some of these concepts.

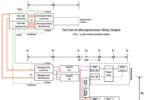
Setting the Stage for Transformation: A 1987 IEEE Article “Microprocessor Relays and Protection Systems” foreshadowed that the transition to a fully virtualized protection future would start with the first step of digitizing the signals. As shown in Figure 1, early MP relays employed an all-in-one approach, in which the digital to analog (D/A) and signal digitization (I/O) was all done in the same box with the microprocessors (mp) – and in many cases all on a single circuit board. Although the concept of separating these components was not limited to IEC 61850 implementations, this article will focus on the capabilities specifically enabled by the IEC 61850 standards.
IEC 61850 allowed, as shown in Figure 2, for the D/A and I/O functions to be split out into a dedicated Process Interface Unit (PIU). The microprocessor functions would then be separated out and referred to as intelligent electronic devices (IEDs).
With the functional separation of these components, the stage was set to fully digitize the substation. In a fully digitized 61850 substation, all currents, voltages and I/O could be represented in various means on one or more networks. And IEDs became nothing more than a glorified computer. Without the need to have complex physical wiring at these devices, the risk profile began to change significantly.
A review of this new arrangement presents a different risk profile versus traditional protection:
- Design Complexity – The functional complexity of the protection and control (P&C) systems can increase while the physical wiring complexity significantly decreases. Routing information to and from an IED from the PIUs becomes a network routing challenge, while the publisher/subscriber configurations are handled in the software designs for the associated devices
- Maintenance – Maintenance is greatly simplified since replacing a PIU only requires working with the actual sources wired to it. For the sake of this article, the assumption will be made that a PIU only has physical wiring to a single breaker, transformer or other equipment. This allows for the most flexibility with respect to integration, maintenance and testing
- Testing – Testing for digital substations is somewhat of a complex topic, as the requirements are heavily dictated by the actual design used. With the right design, it is possible to leverage the built-in testing capabilities of the standard to test the devices while online without any impacts to in-service equipment. It is also possible to do complex full-system functional and integration tests that would be nearly impossible to accomplish with the traditional equivalents
- Processor Workload – Without the magnetics and other hardware needed to support A/D and I/O functions in the IED, the space and ancillary heat in the chassis can be greatly reduced. This allows for more powerful processors and associated heat management to be integrated, and the result is more processing capability. It is not uncommon to see physical IED hardware with the ability to act as a single CPC for an entire portion of a substation
- Failure Exposure – The risks do not necessarily change for the failure of a single IED in a digital substation. Although employing a more comprehensive CPC will increase the exposure for an IED, it is not complicated to add secondary or even tertiary IEDs for redundancy
The Transition to Virtualization
Once the realization sets in that the IED can be nothing more than a glorified computer, a natural series of questions starts to emerge:
- If the IED capability stays the same, can the size shrink?
- If the IED size stays the same, how much more can it do?
- Can generic hardware be used?
- Can the IED be virtualized?
- How are failures managed?
- How is hardware compatibility managed?
- If generic hardware is used, who is liable for failures or mis-operations?
- What’s the best approach to patch management?
- How are cyber security issues managed?
- How is licensing managed in a virtual environment?
- How can performance over time be monitored/managed?
- If everything is digitized, what else can be done?
- And many, many more…
It is not the intent of this article to discuss the merits or technical pros and cons of any aspect of the transition, but to simply paint the landscape that is quickly emerging as a result. The future really is going to be virtualized, but when? There are already virtual IEDs in the production space today, with some having been in service for nearly 20 years. However, there are many questions that need to be addressed before many vendors will bring their products to this space. The rest of this article will focus on a few of these items and hopefully set the stage for future articles and research.
What is Virtualization?
At its core, virtualization is the concept of representing something in the software realm as if it were in the physical or hardware realm. It is a “virtual” version obtained through abstraction from the physical realities on which it really resides.
An original microprocessor implementation might have utilized an embedded operating system or set of processor specific memory registers to create the instruction set that enabled it to function as a relay. As advancements in both microprocessor and specialty chips progressed, high speed calculations could be dumped to highly performant integrated circuits like FPGAs, while standard components were handled by either an embedded or real-time operating system.
When simplified to the basics, every aspect of a microprocessor relay can be implemented in code. As processors have increased in speed, the need for specialty chips like FPGAs has been reduced, enabling a complete implementation with regular hardware. There are many commercial options for virtualizing this hardware, allowing for the code that was once dedicated to a single box to be shared across multiple boxes or instantiated in multiple variants on the same device.
But adding a layer of abstraction between this mission-critical code and the base hardware adds inherent delays. But how much? To understand that it is important to understand how this hardware is virtualized.
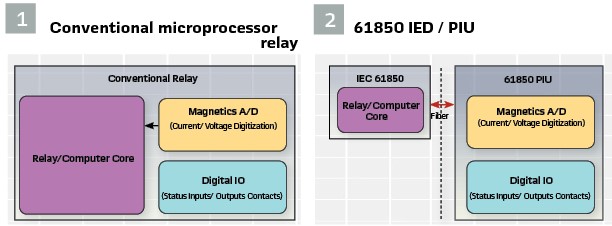
Hypervisor Types: There are two principal types of hypervisors, Type 1 and Type 2. Type 1 hypervisors run directly on the underlying hardware as the system’s operating system. In this role, it has direct access to the hardware’s processor(s), memory, disk, I/O and other functions. These types of hypervisors are highly efficient due to their direct access and control of the underlying hardware. Type 2 hypervisors run as an application on the host system’s operating system. Due to the lack of direct hardware access, the performance of these hypervisors is at the mercy of the efficiencies of the host operating system. (Figure 4).
The mission-critical nature of vPAC systems tend to dictate that they should be run on a type 1 hypervisor. It is imperative that all aspects of the device are optimized such that the protective functions are not compromised through latency or corruption. (Figure 3).
Broadcom VMWare’s ESXi, Citrix XenServer and XCP-ng are popular type 1 hypervisors in the data center space. These hypervisors all take a similar approach of providing their own hypervisor implementation with specialized optimizations to handle specific types of workloads. They take a similar approach in terms of networking, utilizing a virtual switch architecture that somewhat mimics that of a traditional managed switch. Open vSwitch is an example of this.
Linux has a built-in “Kernel-based Virtual Machine” (KVM) that has been present since 2007. The inclusion as a base feature of the Linux kernel makes it a popular implementation choice. Configuration is accomplished through configuration files and command line utilities, making it less user-friendly than other options. There are a few hypervisor solutions that are built on top of the KVM architecture, offering user-friendly user interfaces and advanced configuration options for their users. Proxmox is one of the most popular type 1 hypervisors built on KVM.
KVM’s networking infrastructure is built by directly configuring various network bridges and configuring internal routing between them. Although this allows for some complex implementations, configuration can be complex and confusing, as it doesn’t easily mirror the concepts present in common managed network gear.
Hardware and Hypervisor Interactions: The selected hypervisor and type are just one aspect of the picture. There are many ways that the interaction of the virtual machines and the underlying hardware can be tweaked for optimal performance. This is accomplished through a mix of hardware and software optimizations.
BIOS – How the hardware is presented to the host operating system is equally important. This configuration is done at the BIOS level, with many modern systems providing specialized options to ensure virtualization-friendly access to the host operating system. Certain features like hyper-threading can often hurt latency-sensitive applications and may be disabled on systems that are designed for vPAC applications.
Once the hardware has made it into the host operating system of the hypervisor, what happens then? These resources can be shared in part or in whole to the virtual machines (VM) that are being hosted by the system.
Processors:
- From a processor perspective, the cores of the main system can be selected and shared with the VMs in several different ways. Typically, processor cores are selected and presented to the VM in a virtualized arrangement of the user’s choosing. Four cores might be presented as a single processor with four cores, two processors with two cores or four processors with a single core
- Many hypervisors allow for over-committing of resources. Statistically speaking, many servers spend a lot of time utilizing only a fraction of their CPU or memory resources. By taking advantage of this, companies are able to efficiently stack many servers as virtual machines on a single host. This leads to much better economics in terms of the number of computers required and energy used. However, for latency-sensitive applications, this type of allocation is not ideal
- Many hypervisors allow CPU pinning, which is a concept where the cores are not only virtualized, but specific physical cores are assigned to a VM. This can eliminate inefficiencies created by the host operating system trying to manage workload. For unpinned applications, the hypervisor may move tasks between CPU cores to spread out processing tasks. This allows for a near perfect utilization of the cores, but at the cost of latency. This is due to the physical cost of migrating tasks between cores and the potential impacts to the CPU caching architecture employed at the hardware level
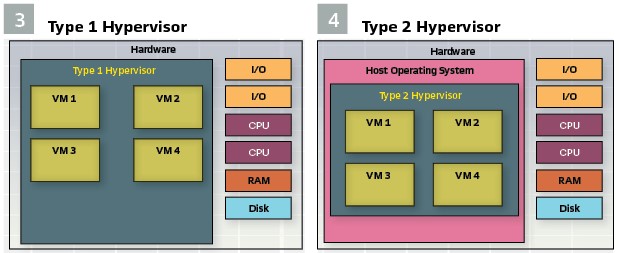
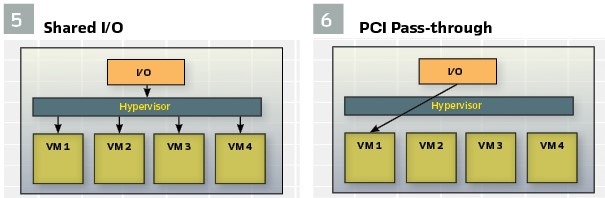
I/O: (see Figures 5/ 6/ 7)
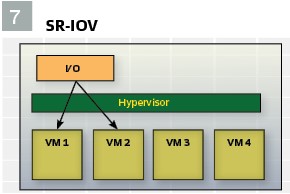
Virtual Machines need to have access to I/O devices to be useful. This can include devices such as network cards for data ingress/egress, Graphics Processing Units (GPUs) for advanced analytics and AI/ML functions or specialty cards for advanced capabilities (e.g. cyber security analytics):
- Most hypervisors create an abstraction layer and do their best to share access to that hardware with all VMs. For network devices, these resources are also shared with the host operating system to allow for advanced network routing or filtering features, but this comes at the cost of latency added by the host OS
- For applications that cannot accept the additional latency, or for VMs that require exclusive access to a resource, most hypervisors support the concept of PCI pass-through, in which exclusive, direct access to the hardware is provided to the VM. This eliminates latency, but at the cost of not allowing the resource to be shared with other VMs on the system, including the host
- PCI pass-through is efficient, but does not contribute to sharing resources, requiring additional hardware for each VM that needs access. This also eliminates flexibility for certain redundancy and failover mechanisms that the host OS can provide. To address this, many manufacturers offer versions of their hardware that supports SR-IOV (Single-Root I/O Virtualization). This allows a single piece of hardware to be shared with multiple VMs through a dedicated I/O lane. The number of VMs are restricted to the number of dedicated lanes a PCI card offers (2,4,8 or more). The abstraction is done at the hardware level on the card, thus providing PCI-passthrough performance, but with the added benefit of being a shared resource
- Some of the most intensive operations involve I/O decoding the layer 2 data frames. The frame counts presented by IEC 61850 protocols can be as high as 4800/sec for 9-2LE protection streams. An example vPAC CPC with 30 bays could see I/O traffic as high as 144,000 frames a second for the SV streams alone, assuming that a single SV stream is sufficient for the protection of the system. If overlapping CT arrangements are needed, the number of required SV streams could easily double. It may be desirable for a system to have dedicated I/O cards with FPGAs to offload decode, cyber security and PRP functions so that the burden of these operations does not fall to the CPU
Leveraging IT Concepts to Improve Availability
With respect to PAC availability, the industry has set a significantly high bar with traditional relays. Hardware designed to provide more traditional IT workloads is not known for longevity, as the typical replacement period in the industry is anywhere from 1/3 to 1/4 the lifespan of currently in-service microprocessor relays. Computer vendors are working to design and certify their equipment to be more resilient in the substation space. But even if they manage to increase the lifespan to meet existing equipment, the meantime between failure (MTBF) rates for this equipment may not meet the needs of the industry.
The architectures of these types of systems open the door for a more rapid and relatively pain-free maintenance cycle. But this only addresses planned maintenance activities. What options are available to improve system availability to match or exceed existing PAC systems? To understand the available solutions, look at the data center space. In the datacenter environment, there are at least two concepts that have the potential to address the availability goals needed by the utility industry.
The simplest is a simple failover scheme. With this approach, the failure of one system results in the startup of a secondary system. There is a time penalty associated with this, and the exact time is highly dependent on whether the failover system is already powered on and spooled up (hot) or if it needs to be spun up after the failure (cold). This approach could easily yield a failover time of 10 seconds or less. Compare that to the time a traditional system would be unavailable in the event of a failure.
It is also possible to leverage configurations that provide always-on redundancy in which a hot spare is instantly routed traffic in the event of a failure. This approach is often referred to as high-availability, as the failover time could be as little as a few milliseconds. However, this approach will require additional hardware, which needs to be factored in when considering maintenance, battery loading and costs of ownership. It is important for the industry to promote designs that are resilient to overall availability. It is also important to collect the relevant data so that the industry has solid numbers on MBTF and availability. Without this approach, it will be difficult for many utilities to justify the transition, as the perceived risk will simply be too high.
Next Generation Capabilities
Having the capability to transition to virtual protection is not an adequate driver for utilities. These types of systems come at considerable costs, especially when considering the full infrastructure needed to support the level of availability that utilities expect. The real drivers will be value added from the next-generation capabilities that come with this class of hardware.
Fully networked digital substations bring access to a host of new data. The ability to analyze the interactions of devices at a station level has the potential to unlock new frontiers in the condition- based maintenance space as new analytics are developed. Current transformers can be analyzed for latent conditions, in real-time. The interaction of faults at a system level can help validate existing protection schemes for operational security or highlight previously unknown interactions between system components. Full breaker monitoring can be accomplished, validating electrical and physical trip times as well as contact performance without placing any additional calculation burden on the associated relays or installing additional sensors.
While GPUs are certainly not required to perform simple AI/ML activities, with their addition, the volume of AI/ML tasks can exponentially increase. It becomes possible to analyze currents and voltages for problem indicators that have not traditionally be detected through traditional fault mechanisms. There are several efforts to build AI/ML models to detect these types of events offline, but with vPAC systems with GPU resources, it becomes possible to look for them in real-time, notifying operators so they can take action before customers are adversely affected.
These types of systems also open the doors for more untraditional approaches like digital twins for real-time protection. These systems can analyze IEC 68150 data to compare actual system data against a running model for fault location and identification, or for more cyber-related activities like evaluating operational data to ensure that the system is not trying to do something that would cause undue harm to the grid.
Challenges for Advancement
There are challenges to making sure that vPAC systems can advance. From a performance perspective, there are still unknowns regarding the various configurations available. It is important to identify critical system performance parameters that will ensure the system will work long into the future. Hypervisors introduce a layer between the protection logic and the hardware on which it runs. It is important to understand how the configuration of this layer and the underlying hardware can impact long-term latency and performance.
There are efforts currently underway to evaluate this type of behavior, and assess how much of an impact non-deterministic hypervisor operating systems could have on protection versus a deterministic environment provided by a real-time operating system or hypervisor.
But even if these behaviors are understood, there is still the challenge of ensuring that a given configuration meets minimum performance specifications needed for a given IED to perform as intended. In the consumer computer market, there are performance scores that evaluate and rank a given system against known specs. One such example is GeekBench(tm), which helps evaluate the effective power of a system’s CPU and GPU arrangement. However, these types of metrics are not designed to evaluate the critical paths important for vPAC systems. The industry needs to develop a standardized suite of tools that can evaluate a fully configured hypervisor for metrics that are critical to vPAC systems. This will help vendors to know that their IED VMs can perform at the desired level. Instead of creating specifications for minimum hardware, the specification can be geared around a minimum vPAC bench score.
There are also integration challenges around standards that will have to be addressed. The current standards have evolved around the concept of a single IED performing the job that a traditional microprocessor or electro-mechanical relay would perform. As such, the provisions are somewhat limited when vendors start to introduce CPCs into the system. Adding virtualization adds another consideration that needs to be specifically considered in the standards.
Conclusion
The future is bright and exciting regarding virtualized protection systems. The limitations of the substation are transitioning physical limitations to a world where the only limits are those provided by the software utilized. Virtualized architectures allow for rapid upgrades, unparalleled redundancy and capabilities that have yet to be dreamt up.
But the road ahead is not without its set of challenges. The architecture and cyber security designs must be robust enough to avoid pitfalls such as those presented by recent events such as the Crowdstrike incident. Transferring knowledge from the IT space to the OT space will be a significant challenge, but it is manageable. The industry and its support groups (vendors, academia, utilities, etc.) need to be aggressively forward-minded so that the continued limitation is only that of the imagination of those implementing it.
Biography:

Glenn Wilson is a research engineer for Southern Company and is based in Birmingham, AL. He has degrees in electrical and computer engineering from Mississippi State University. He has worked in the electric utility industry for over 25 years, with experience in transmission operations, protection and control, transmission maintenance, and geographic information systems. Glenn is currently responsible for research involving substations and transmission lines. He is married to Laura and has two kids, Timothy and Emma.